좀 더 나은 RRF 만들기 - SRRF
Hybrid Retreival에는 크게 RRF (Reciprocal Rank Fusion) 방식과 CC (Convex Combination) 방식이 있다. Hybrid RRF & Hybrid CC
CC 방식에 대해서는 이전의 블로그 글을 참고하자.
이번 글에서는 기존 RRF의 예상되는 문제점과, 그 문제점을 해결하고자 시도한 SRRF에 대해 소개한다. 내용은 모두 pinecone의 논문 An Analysis of Fusion Functions for Hybrid Retrieval의 내용이며, 이 글을 해당 논문의 간단한 정리 및 리뷰 성격으로 봐주시기 바란다.
RRF란?
먼저, RRF가 무엇인지 알 필요가 있다. 메인 아이디어는, semantic 점수와 lexical 점수를 서로 합칠 때에 점수 분포 등이 다르기에, 각 문서의 순위를 활용하여 합치자는 것이다.
서로 다른 retrieval 방법을 이용해 획득한 점수에 따라, 각 문서들은 몇 번째로 높은 점수를 가지고 있는지 순위를 구할 수 있을 것이다. 그렇게 아래 표와 같은 결과를 얻었다 생각해보자.
| 문서 이름 | semantic 순위 | lexical 순위 |
|---|---|---|
| 문서 A | 1 | 5 |
| 문서 B | 4 | 3 |
| 문서 C | 3 | 2 |
어떤 문서가 제일 좋은 문서일까? 여기서 순위만을 활용하자면, 두 semantic과 lexical 순위를 더한 값이 가장 작은 것이 제일 좋은 (쿼리와 관련성이 높은) 문서라고 할 수 있지 않을까?
그렇게 계산을 하면 문서 A는 6, 문서 B는 7, 문서 C는 5로 C가 가장 관련성이 높은 문서라고 결론지을 수 있다.
이러한 원리를 수식화하여 정리한 것이 RRF이다.
여기서
파라미터는 RRF를 처음 제안한 논문에서는 60으로 지정하였다.
그러나, 본 논문에서는파라미터에 여러 값을 지정하고 그 결과를 살펴보며, 해당 값이 hybrid retrieval 성능에 영향을 미친다는 것을 검증하였다. 구체적인 방식과 얼마나 차이가 나는지에 대해서는 원 논문을 살펴보자.
RRF의 문제
RRF는 relevance score 그 자체를 이용하지 않는다. 그렇기 때문에, 점수의 분포에 대한 정보가 손실되는 문제점이 존재한다.
예를 들어보자. 위의 표 예시에서 실제 점수가 아래와 같았다고 해보자.
| 문서 이름 | semantic 순위 | lexical 순위 | semantic 점수 | lexical 점수 |
|---|---|---|---|---|
| 문서 A | 1 | 5 | 0.9 | 0.7 |
| 문서 B | 4 | 3 | 0.1 | 0.71 |
| 문서 C | 3 | 2 | 0.15 | 0.72 |
문서 A의 semantic 점수가 다른 문서에 비해 매우 높지만, 단순 순위를 계산하자 그 정보가 사라진 것을 볼 수 있는가? 만약 점수를 기반으로 hybrid retrieval 점수를 구했다면 당연히 문서 A가 가장 쿼리와 관련성이 높은 문서로 선정되었을 것이다. 하지만 점수를 순위로 바꾸면서, 각 retrieval의 점수 분포와 관련된 정보를 알 수 없어졌다. 그래서 RRF로 계산하면 문서 C가 가장 관련성이 높은 문서로 채택될 것이다.
얼마나 영향을 미칠까?
여기서 알고 싶은 것은 이러한 정보 손실이 실제로 성능에 악영향을 얼마나 끼치는지이다.
그렇다면 일단 정보 손실이 적은 방법이 필요할 것이다.
이제 정보 손실이 적은 RRF 방법을 소개한다.
먼저, sigmoid 함수부터 알아야 한다.
sigmoid 함수
ML을 공부한 분들은 sigmoid 함수가 매우 익숙할 것이다. 기본적인 sigmoid 함수는 아래와 같은 식을 가진다.
이는 아래와 같은 모양의 그래프로 나타나는 것을 알고 있을 것이다.
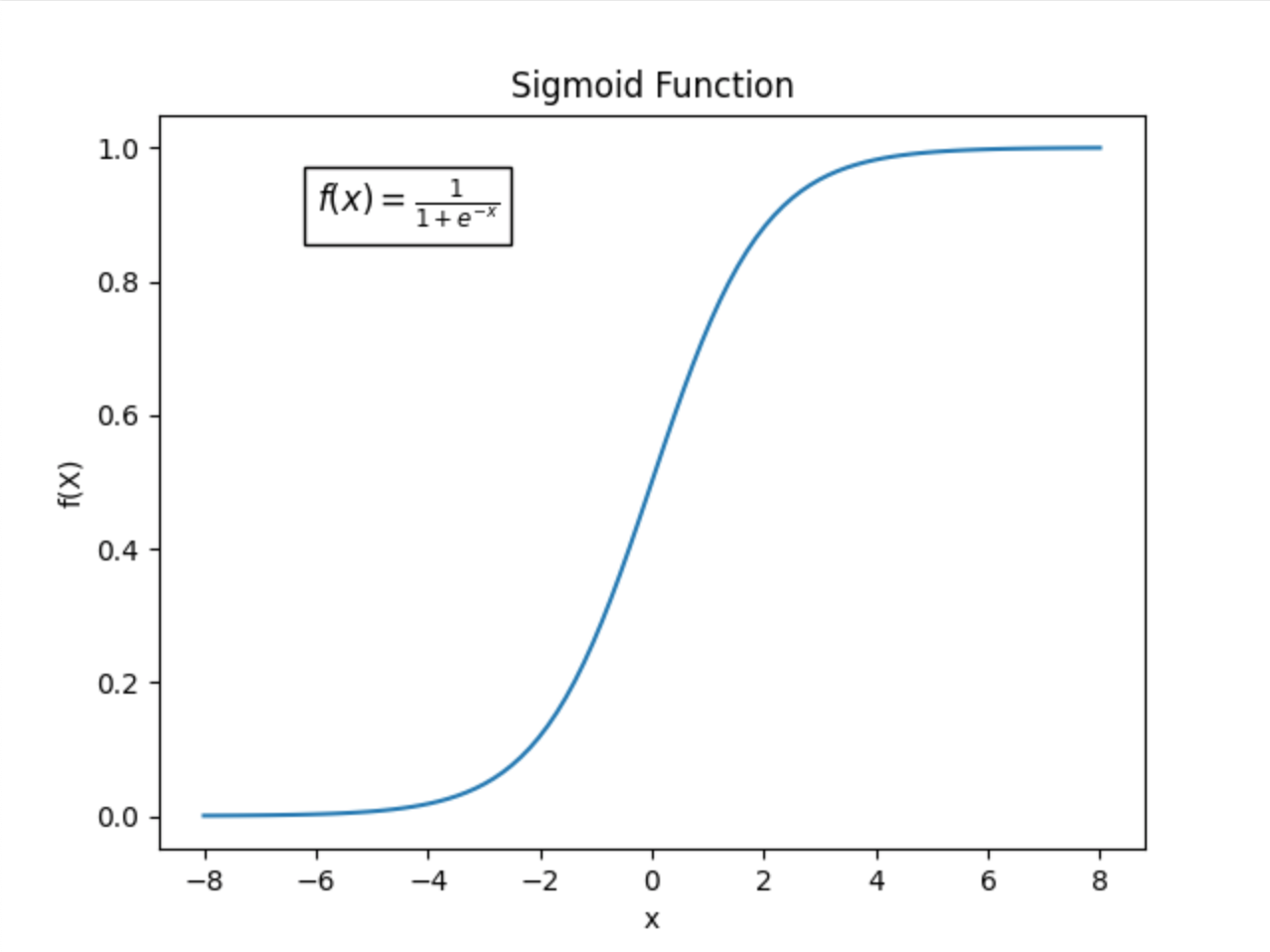
이러한 특성을 활용해서 ML에서는 binary classification의 activation 함수로 많이 쓰인다.
자, 그렇다면 이런 시그모이드 변형 식을 생각해보자.
실제로 그려 확인해보면 다음과 같다.
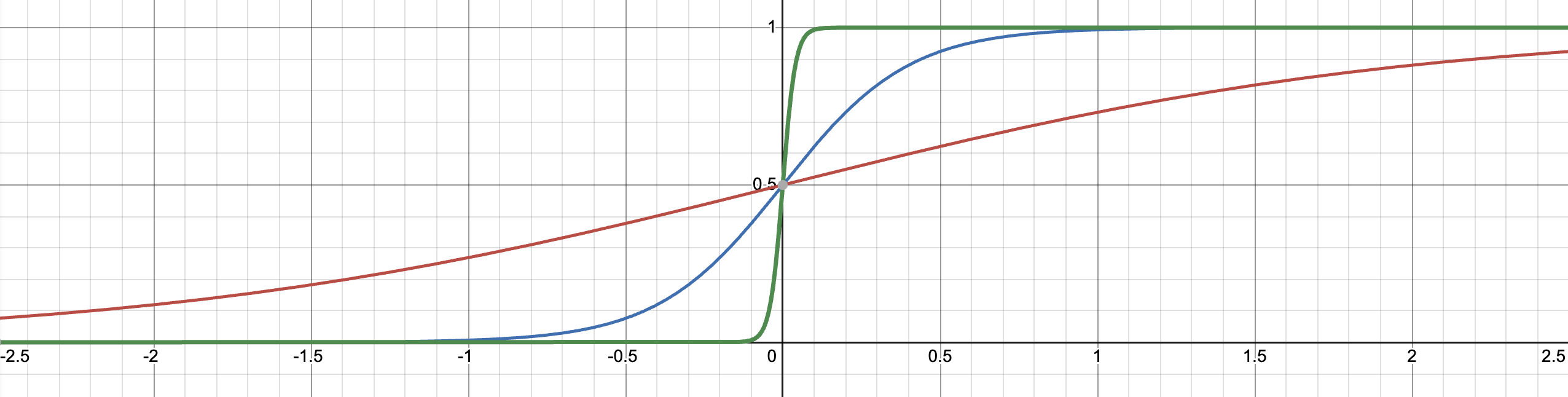
위 차트에서, 빨간색은
sigmoid와 지시 함수
지시 함수라는 용어 등장에 겁먹은 여러분들, 겁먹지 않아도 괜찮다. 생각보다 쉽다.
간단히 말하면, 어떤 조건을 만족하면 1, 아니면 0인 함수이다. 마치 if-else 같은 함수다.
일단, 지시 함수와 sigmoid가 어떻게 관련이 있을까?
이렇게
sigmoid로 RRF 표현하기
앞서서,
여기서
즉, 만약
그렇다면, 지시함수를 sigmoid 함수로 바꿀 수 있다는 것을 기억할 것이다. 지시함수를 sigmoid로 바꾸면 아래와 같이 변한다.
위와 같게 변환할 수 있다.
왜 1이 아니라 0.5를 더해주는 것일까?
그것은 원래 1등의 랭크가 나오는 상황을 생각해보면 쉽다. 만약가 무한대라면 자기 자신을 제외한 모든 문서들의 값은 0이 될 것이다. 하지만, 자기 자신일 경우, 즉 와 가 같을 경우 값이 0이 되므로 은 0.5이다. 그러면 최종 랭크 값이 1이 되기 때문에 앞에 0.5를 더해주는 것이다.
이제 의문이 들 것이다. 왜 이렇게 바꿔준 것이지?
처음으로 돌아가서 생각해 보자. 이 설명을 시작한 이유는 RRF의 점수의 분포를 반영하지 못하는 성질이 실제 성능에 얼마나 악영향을 미치는가를 알아보기 위함이었다.
이를 위해, RRF에 점수의 분포를 반영할 수 있는 방법을 만들어야 했다. 그리고 위
이렇게 변형한 RRF를 SRRF라 하며, 아래와 같이 정리할 수 있다.
원 논문에서는 더 엄밀하게 Lipschitz 연속성과 Lipschitz 상수를 통해 설명한다. 더 정확한 설명을 위해서는 원 논문을 참고하자. 전체적인 흐름은 이 블로그와 크게 다르지 않다.
간단하게만 덧붙이자면, Lipschitz 연속인 경우 (시그모이드 함수는 Lipschitz 연속) Lipschitz 상수가 작을수록 함수를 거친 후에 값의 변동이 적다. 즉, 정보가 잘 보존된다.
여기서는가 곧 Lipschitz 상수이다.
그래서 얼마나 영향을 미치는데?
연구진은
그 결과 값은 아래와 같다.
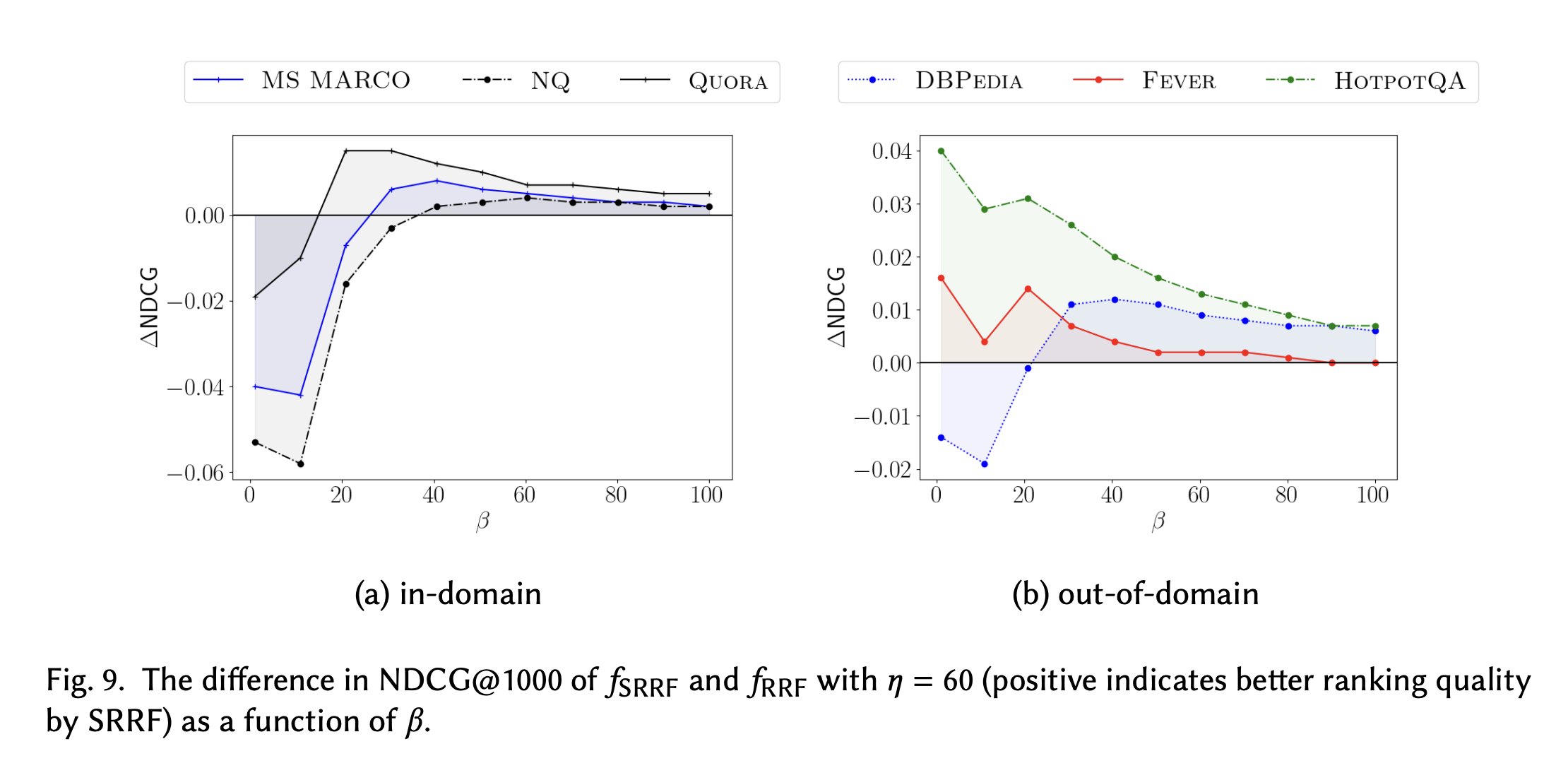
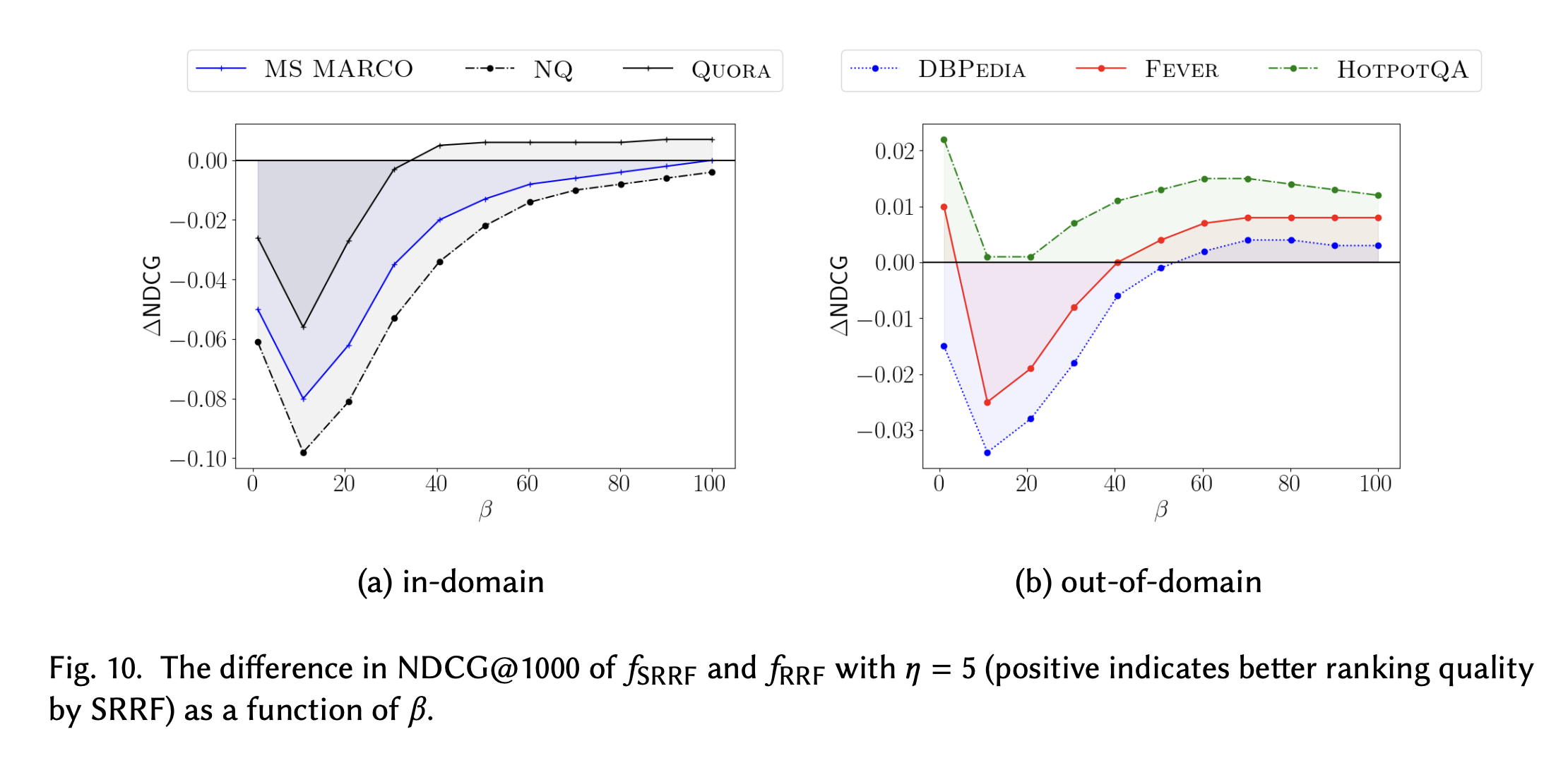
위와 아래 결과의 경우
전반적으로, 너무
반면,
주목할 만한 것은 적당한
CC vs RRF vs SRRF
마지막으로, 이렇게 개선한 SRRF와 다른 Hybrid retrieval 방법인 CC와의 성능 차이가 궁금할 수 있어, 논문의 실험 결과를 첨부한다.
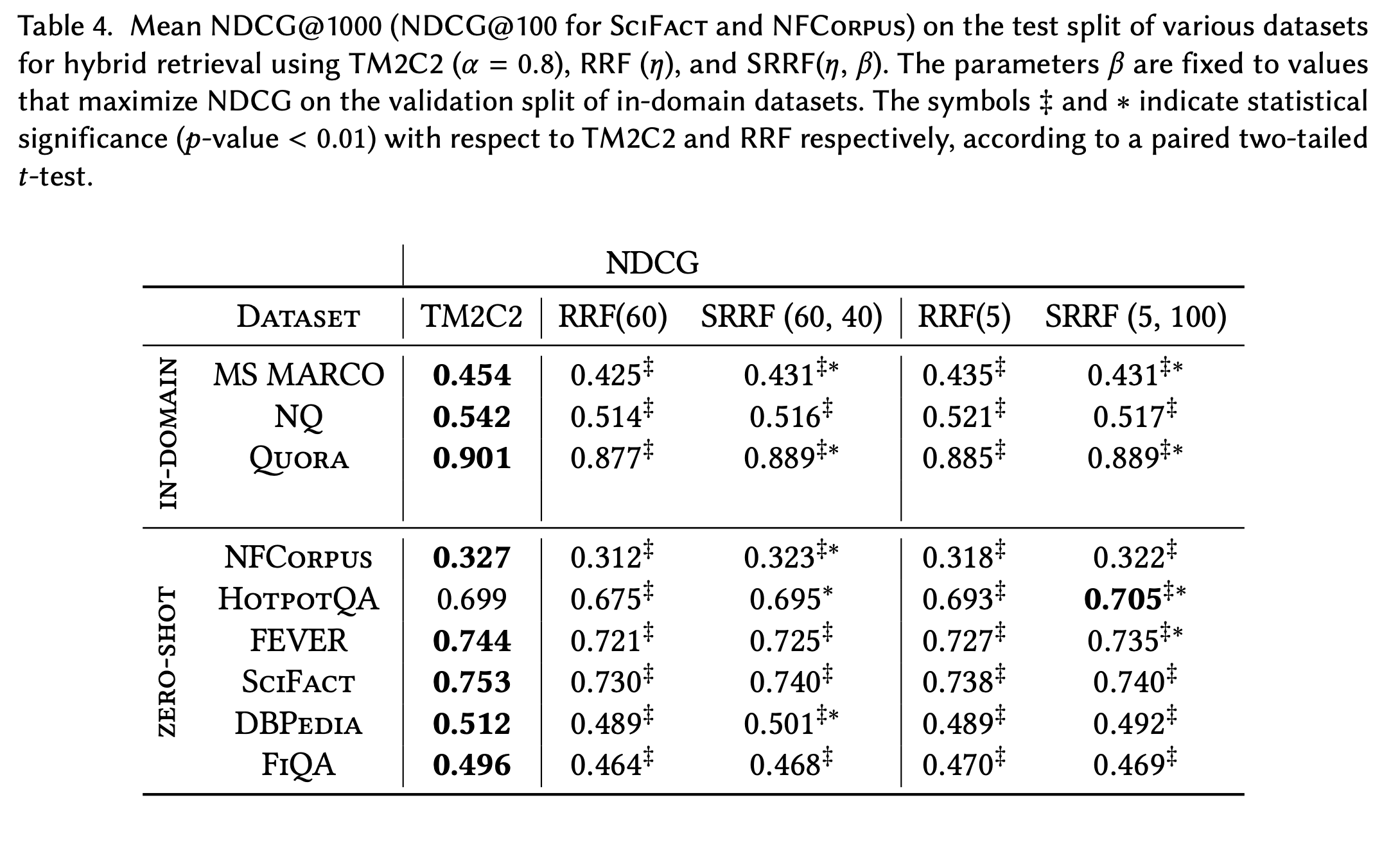
TM2C2는 CC의 tmm normalization 기법을 적용한 것이다. TMM에 대한 설명은 이 블로그 글을 참고하자.
위의 결과 값에서, 대체적으로 RRF보다 SRRF의 성능이 소폭 높음을 관찰할 수 있다.
더불어 주목할 점은, HotpotQA 데이터셋에서 SRRF의 성능이 다섯 개의 retrieval 세팅 중에 가장 높았다는 것이다.
이렇듯, 많은 경우에서는 Hybrid cc (TM2C2)의 성능이 더 우수했지만 SRRF가 더 좋은 대안이 될 수도 있다는 가능성을 볼 수 있다.
AutoRAG에서 사용하기
RAG 자동 최적화 툴인 AutoRAG에서 이런 SRRF를 도입하기 위한 준비를 하고 있다.
해당 깃허브 이슈에서 진행 상황을 확인 가능하다!